Эффективное программирование
личный блог velkin
Превращение кода в карточки
12.04.2025
|
velkin
 |
Читабельный код
Читал на днях книгу "Чистый код" Мартина Роберта главу 2 "Содержательные имена".
Если подвести итоги кратко.
1. Составляйте осмысленные имена.
2. Если код не имеет имён измените его так чтобы они были.
Осмысленные значит программист должен сразу понимать их при прочтении. А сделать имена это замена на конструкции имеющие имена.
Например.
1. Выражение не имеет имени. Заменяем его на функцию и она уже имеет имя.
2. Целочисленный литерал не имеет имени. Заменяем его на числовую константу или перечислитель имеющие имя.
И всё в таком роде.
Рекомендация такая, что нужно читать код как художественную книгу, когда в голове возникают образы. Но откровенно говоря это невозможно. Для меня sqrt такая же закорючка как и square root. То есть нужно писать квадратный корень чтобы я сразу понял без расшифровки переводом.
Я уже больше двух десятилетий назад осознал, что проблема перевода решается направленными асинхронными графами и принципом форм Вирта, но такой программы кодировщика пока что нет. Смысл в том, чтобы не затрагивать исходный код на других языках, таком как английском (square root), английском зашифрованном (sqrt), английском отсебятинском (sq), английском придумаю имя потом (xxx).
Ну хорошо, эту программу надо создать, а что делать сейчас? И вот здесь мне пришла в голову идея.
Были у меня когда-то статьи.
1. Модифицируемость кода (Changeability QA) (08.01.2015)
2. Отсечение целей (сложность разработки) (11.01.2015)
Вариант 1
modify_01.cpp
// begin: заголовочные файлы
#include <stdlib.h>
#include <stdio.h>
// end: заголовочные файлы
// begin: точка входа в приложение
int main(int argc, char* argv[])
{
printf("Hello World!\n");
return EXIT_SUCCESS;
}
// end: точка входа в приложениеВариант 2
modify_02.cpp
#include <stdlib.h> // 2.c
#include <stdio.h> // 3.c
inline void hello_world() // 3.b
{
printf("Hello World!\n");
} // 3.e
int main(int argc, char* argv[]) // 1.b
{
hello_world(); // 3.c
return EXIT_SUCCESS; // 2.c
} // 1.e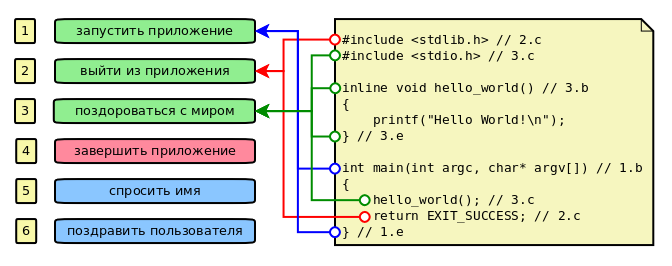
Вариант колоды 1
modify_01_deck.cpp
//
/*-----------------------
-------------------------
-----------------------*/
//-----------------------
/*-----------------------
заголовочные файлы
-------------------------
#включить <стандартная_библиотека.заголовок>
#включить <стандартный_ввод_вывод.заголовок>
-----------------------*/
#include <stdlib.h>
#include <stdio.h>
//-----------------------
/*-----------------------
точка входа в приложение
-------------------------
целое главная(целое количество_аргументов, символ* вектор_аргументов[])
{
форматированная_печать("Привет Мир!\n");
вернуть ВЫХОД_УСПЕХ;
}
-----------------------*/
int main(int argc, char* argv[])
{
printf("Hello World!\n");
return EXIT_SUCCESS;
}
//-----------------------Вариант колоды 2
modify_02_deck.cpp
//
/*-----------------------
-------------------------
-----------------------*/
//-----------------------
/*-----------------------
приложение / библиотека / стандартная
-------------------------
#включить <стандартная_библиотека.заголовок>
-----------------------*/
#include <stdlib.h>
//-----------------------
//
/*-----------------------
привет мир / библиотека / ввод вывод
-------------------------
#включить <стандартный_ввод_вывод.заголовок>
-----------------------*/
#include <stdio.h>
//-----------------------
//
/*-----------------------
функция / привет мир / сигнатура
-------------------------
встроить пустое привет_мир()
-----------------------*/
inline void hello_world()
//-----------------------
//
/*-----------------------
функция / привет мир / начало
-------------------------
{
-----------------------*/
{
//-----------------------
//
/*-----------------------
функция / привет мир / форматированная печать
-------------------------
форматированная_печать("Привет Мир!\n");
-----------------------*/
printf("Hello World!\n");
//-----------------------
//
/*-----------------------
функция / привет мир / конец
-------------------------
}
-----------------------*/
}
//-----------------------
//
/*-----------------------
функция / главная / сигнатура
-------------------------
целое главная(целое количество_аргументов, символ* вектор_аргументов[])
-----------------------*/
int main(int argc, char* argv[])
//-----------------------
//
/*-----------------------
функция / главная / начало
-------------------------
{
-----------------------*/
{
//-----------------------
//
/*-----------------------
функция / привет мир / вызов
-------------------------
привет_мир();
-----------------------*/
hello_world();
//-----------------------
//
/*-----------------------
приложение / выход / успешный
-------------------------
вернуть ВЫХОД_УСПЕХ;
-----------------------*/
return EXIT_SUCCESS;
//-----------------------
//
/*-----------------------
функция / главная / конец
-------------------------
}
-----------------------*/
}
//-----------------------Программа "Учитель"
Текущая версия с помощью которой можно открыть код как колоды.
kisa_teacher_0.6_windows_x86.exe
Или с официального сайта. Хотя нужно понимать, что в некоторых странах вроде России он заблочен. Да и в принципе по прошествии лет ничего не останется от прошлых ссылок.
Итоги
Мне сложно сделать построчный анализ программой для открытия колоды, то есть вариант 2. Потому если запустить код варианта 2 как колоду, то будет видно насколько коряво прописаны пути. Вариант 1 более простой и вряд ли стоит переходить с него на более сложный без особого софта с направленным ациклическим графом. Тем более построчный анализ далёк от анализа терминалами и ниже.
Поможет ли сортировка и фильтрация добавленные в версию 0.6? Во втором варианте вряд ли, в первом возможно, всё же между классами и методами сохраняется иерархия нежели когда используется функционал как отправная точка для сортировки и фильтрации.
К тому же речь шла о том, чтобы читать код. Ну как бы вот можно почитать. Хотя без программы кодировщика никуда не продвинуться, а это не более чем идея на колодах карточек потому, что они уже есть.
Хотя повторю главную мысль статьи. Сколько бы Мартин Роберт в своём "Чистом коде" не говорил о его читаемости, это невозможно осуществить читая чужой код или английский код. Системы мышления разных людей не совместимы даже если они говорят на одном условном языке, не говоря уже о разных языках.
И понятно теперь почему многие программы не имеют вменяемых официальных руководств, обучающих примеров и так далее. Даже в мелком прототипе многие не успевают за функциональностью, если только нет коллектива, который специально над этим работает за деньги.
| 12.04.2025 14 комментариев |
V>Рекомендация такая, что нужно читать код как художественную книгу, когда в голове возникают образы.
Это хорошо что ты читаешь умные книжки.
V>Но откровенно говоря это невозможно.
Возможно.
V>Для меня sqrt такая же закорючка как и square root. То есть нужно писать квадратный корень чтобы я сразу понял без расшифровки переводом.
Вот серьезно да? Это примерно на первом курсе же учат min, max, sqrt, pow, find, get, move, copy и тому подобное.
Мб надо не забивать себе голову векторной галиматьей и тупо запомнить пару тысяч слов.
V>>Для меня sqrt такая же закорючка как и square root. То есть нужно писать квадратный корень чтобы я сразу понял без расшифровки переводом.
GIV>Вот серьезно да? Это примерно на первом курсе же учат min, max, sqrt, pow, find, get, move, copy и тому подобное.
GIV>Мб надо не забивать себе голову векторной галиматьей и тупо запомнить пару тысяч слов.
Дело в том, что я и так помню их перевод, причём как английскую полную расшифровку, так и русскую.
Но для примера цитата из книги.
Ну то есть если я понимаю это так.
1. min, minimal, наименьшее (минимальное).
2. max, maximal, наибольшее (максимальное).
3. sqrt, square root, квадратный корень.
4. pow, power, (в текущем контексте) степень (возведение в степень).
И так далее.
Но Мартин Роберт говорит, что я просто умственно жонглирую.
1. Во-первых, он предлагает не использовать сокращения, а давать полные имена.
2. Во-вторых, для него родной язык английский США, то есть применительно ко мне я должен использовать его советы для языка русский Россия.
И вот здесь я натыкаюсь на фундаментальную проблему. Люди клали болт на полные имена и используют английские сокращения. Лично я предполагаю, что так проще было использовать имена в выражениях. Ну или может ещё что-то из сокращений в математике.
Дело не в том, что я не знаю, что это значит, но процесс выглядит так.
1. Декодирование.
2. Осмысление.
3. Кодирование.
А Мартин Роберт я так понимаю хочет чтобы выглядело так.
1. Осмысление.
Или вот ещё цитата почему он хочет чтобы код можно было прочесть как художественную книгу.
Сюда бы вставить какой-нибудь смешной мемасик про то, что мы постоянно читаем свой старый код. Может Мартин Роберт и читает, но он на то и профессионал. Вот я и подумал, что заставит меня прочитать мой старый код. Написав его на русском, причём именно так как думаю именно я, то возможно я бы его и прочёл снова и снова, а может и нет.
И конечно же стоит вспомнить его и не только его утверждение, что хороший код говорит сам за себя. Но там уже другая четвёртая глава про комментарии и прочее. Из-за чего я и пришёл к идее проверить мысль, что можно написать тот же самый код, но заменить ключевые слова и идентификаторы на полные русские имена. Причём сделать это с помощью комментариев в виде карточек.
Понятно, что можно всё это проигнорировать и продолжить мысленное жонглирование. Но мне стало интересно проверить эти мысли.
Или ещё нашёл статью на тему перевода.
О русском языке в программировании (3 янв 2021)
И сразу началось с того, что Print я перевожу как Печать, а не Вывод, потому что если Ввод это Input, то Вывод для меня это Output. И дальше идёт цепь несовпадений, типа Возврат это Return, хотя я бы предпочёл Вернуть. Причём не то, чтобы я был прав, но ведь это Мартин Роберт хочет чтобы люди читали код как "Властелина колец".
Потому в топике я и написал.
Почему? Да потому что первый же человек с ходу переводит не так как я.
Вопрос здесь в том.
1. Подстраиваемся ли мы под код других.
или
2. Подстраиваем код других под себя.
Конечный результат может быть одним и тем же, тот же код с английскими ключевыми словами и английскими идентификаторами. А вот осмысление может проходить по разному. Как и говорил Мартин Роберт, можно и букву r подменять чем хочешь, а можно написать что это такое не просто на условно родном языке, а на языке собственного мышления.
V>Дело в том, что я и так помню их перевод, причём как английскую полную расшифровку, так и русскую.
Тебе не нужен перевод, тебе смысл нужен. Мне вообще пофиг что значит в английском слово thread, мне когда я читаю код важно что оно значит тут в этом тесте. И если там написать вдруг "нить" это не изменит вообще ничего.
V>Но для примера цитата из книги.
V> r плохое имя, ясен пень.
V>Ну то есть если я понимаю это так.
V>1. min, minimal, наименьшее (минимальное).
V>2. max, maximal, наибольшее (максимальное).
Наболее частые слова хоть в английском, хоть в русском, хоть программе на java имеют тенденцию укорачиваться. Поэтому мы имеем I, Я в английском и русском и +-/* в java. min и max менее часты и поэтому 3 буквы для них норм.
V>2. Во-вторых, для него родной язык английский США, то есть применительно ко мне я должен использовать его советы для языка русский Россия.
Программы не пишут на английском или русском, внезапно. Не вижу никакой разницы между thread.interrupt() и нить.прервать(). Знание слова interrupt или прервать минимально помогает понять что тут происходит.
V>И вот здесь я натыкаюсь на фундаментальную проблему. Люди клали болт на полные имена и используют английские сокращения.
Эээм ты про min чтоли? Фундаментальная проблема?
V>>Дело в том, что я и так помню их перевод, причём как английскую полную расшифровку, так и русскую.
GIV>Тебе не нужен перевод, тебе смысл нужен. Мне вообще пофиг что значит в английском слово thread, мне когда я читаю код важно что оно значит тут в этом тесте. И если там написать вдруг "нить" это не изменит вообще ничего.
Правильно, нужен смысл. Потому для меня thread это поток исполнения, а не thread.
Посмотрел сейчас вики.
1. Thread (computing)
2. Поток выполнения
Получается выполнения, а не исполнения, но это их версия, а у меня в голове сразу пришёл перевод поток исполнения. Но это был именно перевод, а не thread.
Было у меня как-то размышление почему одни программисты эффективнее других. И один из вариантов состоял в том, что одни программисты стали основоположниками наклепав терминов из своей головы. У них всё было хорошо, ведь в их голове это работало просто отлично. А вот остальные разделились на тех кто может с ходу понимать любую галиматью и тех кто не может.
Это по сути тоже самое, что и в медицине, оно же лечение, исцеление. Начинаются всякие термины, на самом деле просто слова с латинского, древнего греческого и так далее. Кардио, сердце. Вита, жизнь. Ну и пошло поехало. В общем закончилось моё размышление на том, что хотя перевод я знаю, но к переводу подключены другие нейроны, что не позволяет создать новые нервные соединения сделав быстрые выводы.
V>Посмотрел сейчас вики.
V>1. Thread (computing)
V>2. Поток выполнения
V>Было у меня как-то размышление почему одни программисты эффективнее других.
Одни смотрят в вики значение каждого слова а другие нет?
V>>Было у меня как-то размышление почему одни программисты эффективнее других.
GIV>Одни смотрят в вики значение каждого слова а другие нет?
Тебе же снова и снова говорят, не совпадает система восприятия, книга "Чистый код" Мартина Роберта. Ещё раз повторяю, с твоей точки зрения по Мартину Роберту, я должен писать код той же буквой r. А потом говорить твоими же словами чтобы ты просто заучил термины.
Ты пишешь.
А почему r плохое, а
опять же по твоему мнению хорошие?
Выучил min, max, sqrt, pow, find, get, move, copy выучишь и r. Но вот Мартин Роберт в книге "Чистый код" считает иначе. Просто его мышление ориентировано на английский США, а мой на русский Россия.
Не нравится r, мало символов? А как насчёт имени mac? Возможно это что-то значит, а возможно и нет.
Ты можешь оставаться при своём мнении, а я пока подумаю над подходом Мартина Роберта.
V>Выучил min, max, sqrt, pow, find, get, move, copy выучишь и r. Но вот Мартин Роберт в книге "Чистый код" считает иначе. Просто его мышление ориентировано на английский США, а мой на русский Россия.
Ты нифига не понял ни меня ни Мартина.
Все знают имена min, max, sqrt, pow, find, get, move, copy
Он если что не против сокращений типа max
V>Не нравится r, мало символов? А как насчёт имени mac? Возможно это что-то значит, а возможно и нет.
Дело не в количестве символов (внезапно).
Если читатели знают, что такое mac значит имя хорошее и пофиг сколько там букв и сокращение это или нет.
V>я пока подумаю над подходом Мартина Роберта.
Удачи)
ЗЫЖ Цитаты из его книги, если что, выделения болдом мои.
V>Не нравится r, мало символов? А как насчёт имени mac? Возможно это что-то значит, а возможно и нет.
r, кстати, может быть и хорошим именем, если мы программируем функцию для вычисления длины/площади окружности.
Поэтому в правильном контексте и mac будет хорошим именем.
Тут уже заметили, что важно понимание понятий, а ярлыки просто запоминаются. Но да, ярлыки должны быть адекватны предметной области, есть более удачные, есть менее, но в целом норм. При обучении программированию не они являются основным источником проблем, это уж точно.
V>Хотя повторю главную мысль статьи. Сколько бы Мартин Роберт в своём "Чистом коде" не говорил о его читаемости, это невозможно осуществить читая чужой код или английский код. Системы мышления разных людей не совместимы даже если они говорят на одном условном языке, не говоря уже о разных языках.
С одной стороны, для профессионала это всё детский сад. Люди учат 5-10 языков программирования на уровне, что довольно свободно читают синтаксис и даже что-то пишут простое без документации. Мне однажды не составило труда вспомнить школьный Бейсик, чтобы помочь юному школьнику. Аналогично Паскаль или Пролог. Иностранных языков образованный человек может знать не один, но английский уж точно. Ты уверен, что надо ориентироваться не на развитие навыков, а на примитивизации материала? Сложную концепцию простыми словами не расскажешь.
С другой стороны, твой подход легко проверяется на школьниках/студентах. Ты пробовал? Если нет, если ради идеи не готов на жертвы, то, как говорят инвесторы, грош цена твоей идее.
В третьих, сейчас есть LLM, которые если и не напишут хорошо код, то объяснить его на любом языке смогут очень хорошо, просто проверь. Также я уверен, что они же способны сгенерировать по коду тебе твои карточки. Напиши хороший Промт, скорми его тому же ЧатуГПТ, скорми код и наслаждайся результатом.
Я читаю твои блоги местные и меня не отпускает впечатление маниловщины. Где применение? За столько-то лет можно было бы на практике проверить десяток подходов подачи материала на живых людях. Сконнектиться с университетом или школой, они всегда рады написать статью, был бы материал. Со стороны кажется, что ты работаешь чисто умозрительно, проверяя гипотезы только и исключительно на себе. Но по всем канонам, так не работает. Ты, как автор, не можешь понять, как это будут воспринимать другие, это тупо невозможно.
N>С другой стороны, твой подход легко проверяется на школьниках/студентах. Ты пробовал? Если нет, если ради идеи не готов на жертвы, то, как говорят инвесторы, грош цена твоей идее.
Чтобы попробовать что-то на ком-то нужна готовая программа. Какое-то время назад я обнаружил интересный принцип, если показывать следующий символ, но не все остальные, то скорее всего можно тренировать людей в режиме зубрилы.
Передняя сторона.
Задняя сторона.
Человек нажимает m.
Задняя сторона.
Человек нажимает e.
Задняя сторона.
Человек нажимает a.
Задняя сторона.
Человек нажимает t.
Ещё одна идея окно подсказки со следующим огромным символом. Могу ли я проверить эффективность этого метода без программы? Нет, не могу.
Более того, первое, что мне сказали ещё по первому прототипу, что нужны готовые карточки. Ну то есть я решил проблему с многострочным полем, даже синтезатор речи какой-никакой приделал, хотя руки не дошли его нормально доделать.
И тут сразу раз, нет готовых карточек, на чём и погорели другие программы. А чтобы сделать карточки нужно больше усилий, чем на создание прототипа. А я даже на создание прототипа забивал, куда уж мне до карточек. Здесь принцип бесплатности вообще не сработает.
И в итоге ситуация, когда телега стоит впереди лошади, то есть вам дали программу, она не супер и автор об этом знает, карточек нет, жрите что дают. Короче все те же самые проблемы, что и у других авторов программ метода интервальных повторений. По сути я пока решил только проблемы, которые меня достали больше всего в других программах, но вылезло куча других проблем.
N>Я читаю твои блоги местные и меня не отпускает впечатление маниловщины. Где применение? За столько-то лет можно было бы на практике проверить десяток подходов подачи материала на живых людях. Сконнектиться с университетом или школой, они всегда рады написать статью, был бы материал. Со стороны кажется, что ты работаешь чисто умозрительно, проверяя гипотезы только и исключительно на себе. Но по всем канонам, так не работает. Ты, как автор, не можешь понять, как это будут воспринимать другие, это тупо невозможно.
Пока что нечего предложить другим людям чтобы это было прямо радикальное улучшение. Даже данная статья это переосмысление на переход от пар название=>сигнатура на русский_код=>код.
А ещё я смотрел другие программы и там на мой взгляд была лажа. И когда я сам писал карточки я понял, что тоже писал лажу. Потом я их исправлял и в итоге опять получалась лажа. Самые лучше образцы карточек получались случайно. А якобы улучшения карточек приводило к их ухудшению. Так я узнал, что у людей есть "контекст", то есть то что они держат в уме, когда читают.
И на фоне этого предлагать что-то людям? Или взять даже данную статью. Я знаю, что это не очень правильный способ и я знаю правильный способ. Но правильный способ ещё нужно запрограммировать.
Дальше встаёт вопрос, можно запрограммировать всё в оперативной памяти, но тогда я буду ограничен её объёмом. А можно сделать подгрузку из баз данных, но нормально это можно сделать только вручную используя архитектуру корпоративных приложений, иначе выйдет такая же тормознутая лажа как у многих других.
Или вот ещё, я знаю, что шрифт должен быть большим, у меня он маленький. Но что с того, это же надо написать нормальный функционал его изменения. В общем нет программы, нет данных. Нет данных, нет проверок на людях.
Но положительные результаты уже есть. Просто я не могу их начать резко использовать, так как это несколько другие методы. А даже если начну, то пройдёт куча времени на мою адаптацию.
Плюс ко всему те кто хочет что-то проверить могут это сделать исходя из моих статей. Но статьи у меня не обладают полнотой и вообще не обучают правильным методикам. Потому в топике я и написал.
То есть на написание методики надо потратить n-часов. Но нет гарантии, что методика правильная пока она не опробована хотя бы на себе. Я, кстати, согласен с теми, кто считает, что программисты должны пользоваться своими программами, иначе они напишут лажу.
В общем чтобы испытывать что-то на ком-то надо сначала сделать то, что хотя бы можно испытывать. Хотя функционал прототипа ещё крайне не развит, но я знаю, что проблема в карточках.
Сделает ли школьник карточки? Сделает ли профессор университета карточки? Нет, они не смогут. Всё что люди могли сделать я видел уже в других программах интервальных повторений и тестирования, вроде архивов Anki, MyTestX и так далее.
Предполагается, что должны быть наборы колод, издатели ещё называют такие сборники паками, то есть несколько колод карт объединены в пак. Так вот сколько должны стоить паки, сколько колоды, сколько карточки.
Жалко ли мне потратить несколько тысяч рублей на обучение чему-либо? Но это так не работает, паков нет, колод нет, карточек нет.
А почему нет? Если хорошенько взглянуть, то они есть, но это лажа. Лажа, которая не работает. Лажа, которую не то, что покупать, но и бесплатно не будешь использовать.
Я вообще считаю, что идея ЕГЭ была замечательной. Плохая реализация, ну уж извините, методисты не были гениями изобретателями, а всего лишь продуктом образовательной системы обучения. Как их образовательная система обучила, так и они пытались обучить других.
Как-то я читал статью жалобу про то, что обучение программированию ужасно плохое. Вроде всё правильно написано, но в комментариях человек затребовал хорошую методику обучения. А ему начали говорить, что ты дескать должен вкалывать по непонятным принципам чтобы чему-то обучиться.
Началось всё это бла бла бла. Как спросишь людей как? И начинает описываться нечто общее и размытое. Но я действительно считаю, что если метод сработает на мне, то он достоин распространения. Метод работает, хотя как я выше написал есть принципы немного лучше. А вот данных для обучения пока что нет.
И я ещё раз повторюсь, если бы было нечто работающее, то я бы наверное просто это купил, а не занимался ерундой. Я в этом плане такой же как и другие, зачем напрягаться, когда можно купить, но этого попросту нет. Может я плохо искал, но никто из участников форума тоже ничего нового не сказал.
N>Ты уверен, что надо ориентироваться не на развитие навыков, а на примитивизации материала? Сложную концепцию простыми словами не расскажешь.
Собственно на это и расчёт, только сложный навык можно раздробить на огромное количество мелких и повторять их обособленно. Как игра на пианино, не обязательно играть всю партию, играешь по маленьким частям и продвигаешь пока не запомнишь. Только всё равно кому-то придётся написать произведение.
В общем если есть идеи, то форум и существует для их коллективного обсуждения. Пока что они мало кому интересны, точнее никому неинтересны. Всё потому что людям нужны готовые решения решающие их проблемы, а не идеи.
Между прочим в статье про открытие школы программирования говорилось, что покупателями образования являются женщины за 30, то есть мамаши подросших детей. Школьникам неинтересно вкладывать в своё образование деньги. Учителя, профессора, маэстро, все они лишь кормятся, но не вкладывают деньги.
А ещё я читал другую статью про то как человек написал софт про что-то связанное с печатью. Но он не учёл, что его софт подрывает чужой бизнес по заправке картриджей, ну или что-то такое. То есть прикол в том, что правильно работающая методика компьютерного обучения подорвала бы бизнес учителей, школ и университетов.
V>Чтобы попробовать что-то на ком-то нужна готовая программа. Какое-то время назад я обнаружил интересный принцип, если показывать следующий символ, но не все остальные, то скорее всего можно тренировать людей в режиме зубрилы.
Хорошо. Но что мешает использовать LLM по назначению и генерировать ими карточки?
V>Между прочим в статье про открытие школы программирования говорилось, что покупателями образования являются женщины за 30, то есть мамаши подросших детей. Школьникам неинтересно вкладывать в своё образование деньги. Учителя, профессора, маэстро, все они лишь кормятся, но не вкладывают деньги.
Ой, вот это всё разводилово — обучать женщин программированию. Я не видел ни одного, ни одного хорошего программиста, который бы не упарывался в своё время круглосуточно, по ночам и выходным в работу. Это нравится, это увлекает и когда попадается что-то интересное, невозможно ни есть, ни спать, пока это не закодишь.
Обучить программированию на курсах практически невозможно, если этот процесс рассматривать, как получение обычной профессии. У женщин после рождения детей такого времени нет. Если есть, то они обучатся ей без всяких курсов, хватит великого множества бесплатных книг, курсов и видео.
V>А ещё я читал другую статью про то как человек написал софт про что-то связанное с печатью. Но он не учёл, что его софт подрывает чужой бизнес по заправке картриджей, ну или что-то такое. То есть прикол в том, что правильно работающая методика компьютерного обучения подорвала бы бизнес учителей, школ и университетов.
Так оно сейчас и пытается развиться: раз, два, три.
Текущий тренд — это индивидуальное обучение с нейросетками, вставлю цитату от одного евангелиста:
Звучит во много фантастично, но по факту, сейчас уже полно курсов по типу "Учим английский вместе с ChatGPT". Всё к этому и идёт.
Всё есть
ложкакарточка. Ты мозг-карточка.G>Всё есть
ложкакарточка. Ты мозг-карточка.Мышление идёт только в голове. По сути карточки не могут мыслить, это закодированная в виде символов информация. Фактически символы уже представляют собой связь с образами объектов или действий, то есть являются карточкой в мозгу. Вот почему одна или две стороны карточки могут быть образами представляющими объекты реального мира, а не просто символами имеющими символические значения и не похожие на объекты реального мира.
G>>Всё есть
ложкакарточка. Ты мозг-карточка.V>Мышление идёт только в голове. По сути карточки не могут мыслить
Смарт-карточка на блокчейне с внедрённым ИИ
V>>действий, то есть являются карточкой в мозгу. Вот почему одна или две стороны карточки
Многомерные карточки