Эффективное программирование
личный блог velkin
Катастрофа ООП и многомерные модели данных
21.10.2021
|
velkin
 |
Катастрофа ООП
Перевод статьи: Объектно-ориентированное программирование — катастрофа на триллион долларов
C++ — ужасный объектно-ориентированный язык. Ограничение вашего проекта до C означает, что люди не напортачат ни с какой идиотской «объектной моделью».
Линус Торвальдс, создатель Linux
...
Методы или свойства, которые обеспечивают доступ к определённым полям, не лучше, чем непосредственное изменение значения поля. Не имеет значения, изменяете ли вы состояние объекта с помощью необычного свойства или метода, результат один и тот же — изменённое состояние.
...
Падение четырёх столпов:
1) Абстракция.
2) Наследование.
3) Инкапсуляция.
4) Полиморфизм.
Модель данных
В классической теории, модель данных это формальная теория представления и обработки данных.
Структуры и классы
Для начала создам структуру и класс на языке C++ в обобщённой парадигме программирования. В общем и целом можно считать, что я создаю массивы разнородных элементов или разнородные массивы (гетерогенные), в противовес однородным (гомогенным). Учитывая неизменность количества элементов их можно считать статическими в противовес динамическим.
// структура прямоугольника
template <typename TValue>
struct SRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
};
// класс прямоугольника
template <typename TValue>
class CRectangle
{
public:
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
};
void print_srectangle(const SRectangle<double>& srectangle)
{
qDebug() << "x = " << srectangle.x
<< "y = " << srectangle.y
<< "width = " << srectangle.width
<< "height = " << srectangle.height;
}
void print_crectangle(const CRectangle<double>& crectangle)
{
qDebug() << "x = " << crectangle.x
<< "y = " << crectangle.y
<< "width = " << crectangle.width
<< "height = " << crectangle.height;
}
void using_rectangle()
{
SRectangle<double> srectangle;
CRectangle<double> crectangle;
print_srectangle(srectangle);
print_crectangle(crectangle);
}
/*
Вывод using_rectangle:
x = 0 y = 0 width = 0 height = 0
x = 0 y = 0 width = 0 height = 0
*/Код работает, но только потому, что я добавил в класс модификатор доступа public, то есть открытый доступ. А по хорошему я не должен дописывать ничего подобного, чтобы разграничить подходы, где структура похожа на структуру Си, пусть и в парадигме обобщённого программирования C++, а класс это тот самый новый ООП подход при переходе от Си к C++.
// класс прямоугольника
template <typename TValue>
class CRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
};
void print_crectangle(const CRectangle<double>& crectangle)
{
qDebug() << "x = " << crectangle.x // ошибка: 'x' is a private member of 'CRectangle<double>'
<< "y = " << crectangle.y // ошибка: 'y' is a private member of 'CRectangle<double>'
<< "width = " << crectangle.width // ошибка: 'width' is a private member of 'CRectangle<double>'
<< "height = " << crectangle.height; // ошибка: 'height' is a private member of 'CRectangle<double>'
}Инкапсуляция и свойства
Ошибки произошли потому, что я неявно использовал часть инкапсуляции, то есть механизм сокрытия данных.
Инкапсуляция (англ. encapsulation, от лат. in capsula) — в информатике размещение в одном компоненте данных и методов, которые с ними работают. В реализации большинства языков программирования (C++, C#, Java и другие), обеспечивает механизм сокрытия, позволяющий разграничивать доступ к различным компонентам программы.
Но что если мне нужен доступ к закрытым полям данных. На помощь приходит шаблон проектирование "Свойство". Одни и те же шаблоны проектирования можно реализовывать по разному. Воспользуюсь самым примитивным известным мне способом.
// структура прямоугольника
template <typename TValue>
struct SRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
};
// класс прямоугольника
template <typename TValue>
class CRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
public:
inline const TValue& get_x() const { return x; }
inline const TValue& get_y() const { return y; }
inline const TValue& get_width() const { return width; }
inline const TValue& get_height() const { return height; }
inline void set_x(const TValue& x) { this->x = x; }
inline void set_y(const TValue& y) { this->y = y; }
inline void set_width(const TValue& width) { this->width = width; }
inline void set_height(const TValue& height) { this->height = height; }
};
void print_srectangle(const SRectangle<double>& srectangle)
{
qDebug() << "x = " << srectangle.x
<< "y = " << srectangle.y
<< "width = " << srectangle.width
<< "height = " << srectangle.height;
}
void print_crectangle(const CRectangle<double>& crectangle)
{
qDebug() << "x = " << crectangle.get_x()
<< "y = " << crectangle.get_y()
<< "width = " << crectangle.get_width()
<< "height = " << crectangle.get_height();
}
void using_rectangle()
{
SRectangle<double> srectangle;
CRectangle<double> crectangle;
print_srectangle(srectangle);
print_crectangle(crectangle);
srectangle.x = 1;
srectangle.y = 2;
srectangle.width = 3;
srectangle.height = 4;
print_srectangle(srectangle);
crectangle.set_x(5);
crectangle.set_y(6);
crectangle.set_width(7);
crectangle.set_height(8);
print_crectangle(crectangle);
}
/*
Вывод using_rectangle:
x = 0 y = 0 width = 0 height = 0
x = 0 y = 0 width = 0 height = 0
x = 1 y = 2 width = 3 height = 4
x = 5 y = 6 width = 7 height = 8
*/Пример стал чуть ближе к классическому классу, можно было бы даже заменить print_crectangle на CRectangle.print(). Тем не менее разница в количестве кода по сравнению со структурой на лицо, а ведь здесь ещё нет ни конструктора с деструктором, ни много чего ещё.
Вычисление площади прямоугольника
Для начала вычислю площадь прямоугольника внешней функцией.
// площадь прямоугольника
template <typename TValue>
TValue rectangle_area(const TValue& width, const TValue& height)
{
return width * height;
}
void using_rectangle()
{
SRectangle<double> srectangle;
CRectangle<double> crectangle;
print_srectangle(srectangle);
print_crectangle(crectangle);
srectangle.x = 1;
srectangle.y = 2;
srectangle.width = 3;
srectangle.height = 4;
print_srectangle(srectangle);
crectangle.set_x(5);
crectangle.set_y(6);
crectangle.set_width(7);
crectangle.set_height(8);
print_crectangle(crectangle);
qDebug() << "srectangle_area = " << rectangle_area(
srectangle.width, srectangle.height);
qDebug() << "crectangle_area = " << rectangle_area(
crectangle.get_width(), crectangle.get_height());
}
/*
Вывод using_rectangle:
x = 0 y = 0 width = 0 height = 0
x = 0 y = 0 width = 0 height = 0
x = 1 y = 2 width = 3 height = 4
x = 5 y = 6 width = 7 height = 8
srectangle_area = 12
crectangle_area = 56
*/Метод класса
А теперь встрою функцию в класс, в общей терминологии сделаю её методом, в терминологии C++ функцией-членом класса.
// структура прямоугольника
template <typename TValue>
struct SRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
};
// класс прямоугольника
template <typename TValue>
class CRectangle
{
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
public:
inline const TValue& get_x() const { return x; }
inline const TValue& get_y() const { return y; }
inline const TValue& get_width() const { return width; }
inline const TValue& get_height() const { return height; }
inline void set_x(const TValue& x) { this->x = x; }
inline void set_y(const TValue& y) { this->y = y; }
inline void set_width(const TValue& width) { this->width = width; }
inline void set_height(const TValue& height) { this->height = height; }
TValue rectangle_area() const { return width * height; }
};
void print_srectangle(const SRectangle<double>& srectangle)
{
qDebug() << "x = " << srectangle.x
<< "y = " << srectangle.y
<< "width = " << srectangle.width
<< "height = " << srectangle.height;
}
void print_crectangle(const CRectangle<double>& crectangle)
{
qDebug() << "x = " << crectangle.get_x()
<< "y = " << crectangle.get_y()
<< "width = " << crectangle.get_width()
<< "height = " << crectangle.get_height();
}
// площадь прямоугольника
template <typename TValue>
TValue rectangle_area(const TValue& width, const TValue& height)
{
return width * height;
}
void using_rectangle()
{
SRectangle<double> srectangle;
CRectangle<double> crectangle;
print_srectangle(srectangle);
print_crectangle(crectangle);
srectangle.x = 1;
srectangle.y = 2;
srectangle.width = 3;
srectangle.height = 4;
print_srectangle(srectangle);
crectangle.set_x(5);
crectangle.set_y(6);
crectangle.set_width(7);
crectangle.set_height(8);
print_crectangle(crectangle);
qDebug() << "srectangle_area = " << rectangle_area(
srectangle.width, srectangle.height);
qDebug() << "crectangle_area = " << crectangle.rectangle_area();
}
/*
Вывод using_rectangle:
x = 0 y = 0 width = 0 height = 0
x = 0 y = 0 width = 0 height = 0
x = 1 y = 2 width = 3 height = 4
x = 5 y = 6 width = 7 height = 8
srectangle_area = 12
crectangle_area = 56
*/Повторное использование функций
Всё по прежнему работает, как в обобщённой структуре, так и в обобщённом ООП классе, но именно здесь произошёл первый существенный сдвиг парадигм, за который ругают ООП. До сих пор структура и класс использовались лишь для создания и удаления данных, то есть выделение для них места в памяти и очистка этой самой памяти.
Вот две алгоритмически абсолютно одинаковые функции.
// площадь прямоугольника
template <typename TValue>
TValue rectangle_area(const TValue& width, const TValue& height)
{
return width * height;
}
// что-то там
template <typename TValue>
TValue something_there(const TValue& some_value, const TValue& another_value)
{
return some_value * another_value;
}Но сделав функцию методом, а потом и прибив её к внутреннему состоянию класса мы сделали алгоритм не повторно используемым.
class CRectangle
{
// начало блока описывающего внутреннее состояние класса
TValue x = 0;
TValue y = 0;
TValue width = 0;
TValue height = 0;
// конец блока описывающего внутреннее состояние класса
public:
inline const TValue& get_x() const { return x; }
inline const TValue& get_y() const { return y; }
inline const TValue& get_width() const { return width; }
inline const TValue& get_height() const { return height; }
inline void set_x(const TValue& x) { this->x = x; }
inline void set_y(const TValue& y) { this->y = y; }
inline void set_width(const TValue& width) { this->width = width; }
inline void set_height(const TValue& height) { this->height = height; }
// использование внутреннего состояния класса вне свойств
TValue rectangle_area() { return width * height; }
};Конечно, можно извратиться, для этого существует шаблон проектирования делегирование или даже просто делегирование к функции (функции не члена) из метода (функции члена).
Наследование и делегирование
А ещё я с самого начала специально создал структуру и класс прямоугольника и поместил в них все поля скопом.
Хотя разумно было бы разделить поля прямоугольника на:
1) Двухмерная координата (она же точка).
2) Двухмерный размер.
С точки зрения абстракций это частный случай многомерных координат (точек) и многомерных размеров. На практике это может быть не так. Но давайте предполжим, что я бы сделал разделение.
// структура двухмерной координаты
template <typename TValue>
struct SCartesianPoint2D
{
TValue x = 0;
TValue y = 0;
};
// структура двухмерного размера
template <typename TValue>
struct SSize2D
{
TValue width = 0;
TValue height = 0;
};
// структура прямоугольника
template <typename TValue>
struct SRectangle
{
SCartesianPoint2D<TValue> cartesian_point2d;
SSize2D<TValue> size2d;
};
// класс двухмерной координаты
template <typename TValue>
class CCartesianPoint2D
{
TValue x = 0;
TValue y = 0;
public:
inline const TValue& get_x() const { return x; }
inline const TValue& get_y() const { return y; }
inline void set_x(const TValue& x) { this->x = x; }
inline void set_y(const TValue& y) { this->y = y; }
};
// класс двухмерного размера
template <typename TValue>
class CSize2D
{
TValue width = 0;
TValue height = 0;
public:
inline const TValue& get_width() const { return width; }
inline const TValue& get_height() const { return height; }
inline void set_width(const TValue& width) { this->width = width; }
inline void set_height(const TValue& height) { this->height = height; }
// площадь прямоугольника в классе размер
TValue rectangle_area() const { return width * height; }
};
// класс прямоугольника
template <typename TValue>
class CRectangle
{
// начало блока описывающего внутреннее состояние класса
CCartesianPoint2D<TValue> cartesian_point2d;
CSize2D<TValue> size2d;
// конец блока описывающего внутреннее состояние класса
public:
inline const CCartesianPoint2D<TValue>& get_cartesian_point2d() const
{ return cartesian_point2d; }
inline const CSize2D<TValue>& get_size2d() const { return size2d; }
inline void set_cartesian_point2d(const TValue& cartesian_point2d)
{ this->cartesian_point2d = cartesian_point2d; }
inline void set_size2d(const TValue& size2d) { this->size2d = size2d; }
// лишнее делегирование
inline const TValue& get_x() const { return cartesian_point2d.get_x(); }
inline const TValue& get_y() const { return cartesian_point2d.get_y(); }
inline const TValue& get_width() const { return size2d.get_width(); }
inline const TValue& get_height() const { return size2d.get_height(); }
inline void set_x(const TValue& x) { cartesian_point2d.set_x(x); }
inline void set_y(const TValue& y) { cartesian_point2d.set_y(y); }
inline void set_width(const TValue& width) { size2d.set_width(width); }
inline void set_height(const TValue& height) { size2d.set_height(height); }
// площадь прямоугольника в классе прямоугольник
TValue rectangle_area() const { return size2d.get_width() * size2d.get_height(); }
};
void print_srectangle(const SRectangle<double>& srectangle)
{
qDebug() << "x = " << srectangle.cartesian_point2d.x
<< "y = " << srectangle.cartesian_point2d.y
<< "width = " << srectangle.size2d.width
<< "height = " << srectangle.size2d.height;
}
void print_crectangle(const CRectangle<double>& crectangle)
{
qDebug() << "x = " << crectangle.get_x()
<< "y = " << crectangle.get_y()
<< "width = " << crectangle.get_width()
<< "height = " << crectangle.get_height();
}
// площадь прямоугольника
template <typename TValue>
TValue rectangle_area(const TValue& width, const TValue& height)
{
return width * height;
}
// что-то там
template <typename TValue>
TValue something_there(const TValue& some_value, const TValue& another_value)
{
return some_value * another_value;
}
void using_rectangle()
{
SRectangle<double> srectangle;
CRectangle<double> crectangle;
print_srectangle(srectangle);
print_crectangle(crectangle);
srectangle.cartesian_point2d.x = 1;
srectangle.cartesian_point2d.y = 2;
srectangle.size2d.width = 3;
srectangle.size2d.height = 4;
print_srectangle(srectangle);
crectangle.set_x(5);
crectangle.set_y(6);
crectangle.set_width(7);
crectangle.set_height(8);
print_crectangle(crectangle);
qDebug() << "srectangle_area = " << rectangle_area(
srectangle.size2d.width, srectangle.size2d.height);
qDebug() << "crectangle_area = " << crectangle.rectangle_area();
qDebug() << "crectangle_area = " << crectangle.get_size2d().rectangle_area();
}
/*
Вывод using_rectangle:
x = 0 y = 0 width = 0 height = 0
x = 0 y = 0 width = 0 height = 0
x = 1 y = 2 width = 3 height = 4
x = 6 y = 0 width = 7 height = 8
srectangle_area = 12
crectangle_area = 56
crectangle_area = 56
*/В классе появилось лишнее делегирование, хотя это позволяет мне не менят код вывода значений. И хотя мои примеры чисто условны, тоже самое будет к примеру в такой библиотеке как Qt. Там тоже любят подобное сквозное делегирование всего и вся.
Так же я получил дубликаты вычисления площади прямоугольника, один метод находится в классе размера, другой в классе прямоугольника, причём делегирование не используется. А я ещё мог бы в классе размера назвать этот медод size_area или просто area, так же как и в классе CRectangle.
Но проблема не просто в том, что код дублируется многократно. Казалось бы не дублируй и всё. Но кто в наше время пишет свои велосипеды, разве что для обучения. А по факту имеем фрейморки, и классы прямоугольников от разных поставщиков:
1) вендор VasjaPupkin: VPRectangle.
2) вендор Qt: QRect.
И так далее.
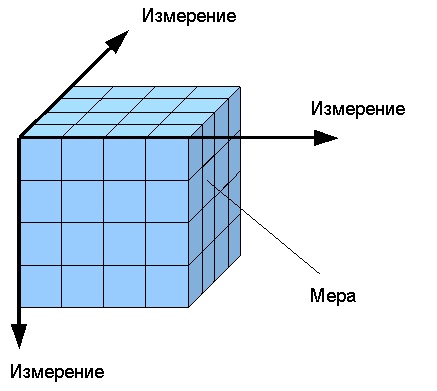
Многомерные модели данных
Существуют другие способы работать с моделями данных.
OLAP (англ. online analytical processing, интерактивная аналитическая обработка) — технология обработки данных, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу.
Или взять Lua, там нет классов и прочего, а есть таблицы.
OLAP-куб — (On-Line Analytical Processing — интерактивный анализ данных) многомерный массив данных, как правило, разреженный и долговременно хранимый, используемый в OLAP. Может быть реализован на основе универсальных реляционных СУБД или специализированным программным обеспечением.
Структура OLAP-куба
Хранилища данных Основы технологии хранилищ данных
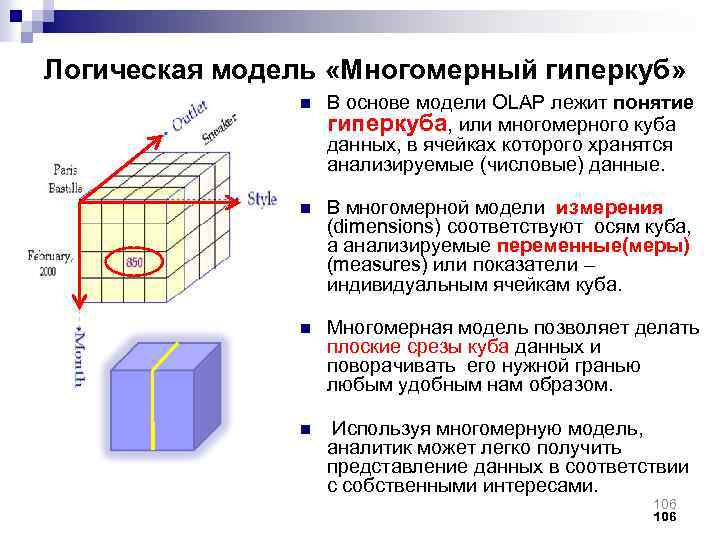
Данные как гиперкуб

Тессера́кт (от др.-греч. τέσσαρες ἀκτῖνες — «четыре луча») — четырёхмерный гиперкуб, аналог обычного трёхмерного куба в четырёхмерном пространстве.
Гиперку́б — обобщение куба на случай с произвольным числом измерений.
Количество измерений:
1) последовательность
2) квардрат (прямоугольник)
3) куб (параллепипед)
4) тессеракт
n) гиперкуб
Количество элементов вдоль одного измерения:
0) нет элементов.
1) фиксированное 1 элемент.
n) фиксированное больше одного элемента.
∞) изменяемое бесконечное количество элементов.
Диапазоны количества элеметов в последовательности:
1) минимальное 0, 1, n
2) максимальное 1, n, ∞
| кол-во элементов | однородные типы | разнородные типы |
|---|---|---|
| 0..1 | ||
| 0..n | ||
| 0..∞ | динамический массив | |
| 1..1 | значение | вариант |
| 1..n | ||
| 1..∞ | ||
| n..n | статический массив | структура |
| n..∞ |
| одномерное | двухмерное | трёхмерное | четырёхмерное | ... | n-мерное |
|---|---|---|---|---|---|
| #..# | |||||
| #..# | #..# | ||||
| #..# | #..# | #..# | |||
| #..# | #..# | #..# | #..# | ||
| #..# | #..# | #..# | #..# | #..# | |
| #..# | #..# | #..# | #..# | #..# | #..# |
Итоги
Всё это были просто размышлизмы с простейшими примерами. На основе этого рано делать какие-либо выводы. Но можно обсудить кто что думает.
| 21.10.2021 17 комментариев |
V>Катастрофа ООП
Нет никакой катастрофы. Просто любой инструмент надо использовать по назначению, что бы решать поставленную задачу в заданных ограничениях.
А не ради следования шаблонам, без каких либо ограничений.
ps: настоящий физик может писать фортраном на любом языке.
V>Всё это были просто размышлизмы с простейшими примерами. На основе этого рано делать какие-либо выводы. Но можно обсудить кто что думает.
В процессе освоения новых инструментов разработчик проходит несколько этапов. Начинается всё со знакомства с новым, проявление интереса, изучение предмета вожделения и, если инструмент действительно чего-то стоит, то и очарования. Заканчивается это всё неосознанным бесконтрольным и главное безудержным применением. Это неизбежно приводит к проблемам от неправильного использования, и как результат сначала к недоумению, а затем и к разочарованию. Далее следуют осмысление и уже осмысленное применение инструмента.
Это в идеале. Очень часто разработчики останавливаются на этапе неосознанного бесконтрольного применения и предпочитают не замечать проблем и даже гневно их отрицать, т.к. признание этих проблем инстинктивно воспринимается как личная трагедия. Как же, всем уши прожужжал, а получилось как всегда.
Поздравляю! Ты этот этап успешно преодолел и у тебя наступило разочарование. Почему поздравляю? Потому что разочарование — это избавление от очарования и иллюзий.
На этом, кстати, многие тоже останавливаются. Ведь гораздо проще кидаться какашками (которых у нас теперь полные карманы), чем включить мозг и проанализировать не только плюсы, но и минусы применения инструмента, найти границы его применимости и совместимости с другими инструментами.
Не стоит надолго задерживаться на этом этапе. Смело переходи к осмыслению и осмысленному применению.
Аминь!
V>
Катастрофа ООП
Пролистал статью. Потом пролистал вверх, поискал буквы НИКС. Не нашел. По сути: ООП — это полезный инструмент организации кода, а не религия. Нет у объекта никаких мистических свойств объектов реального мира, это всего лишь набор фич, которые на практике оказались удобны и хорошо сочетаются. Как перейти от разочарования в ООП к промышленному его применению? Только практика.
V>Код работает, но только потому, что я добавил в класс модификатор доступа public, то есть открытый доступ. А по хорошему я не должен дописывать ничего подобного, чтобы разграничить подходы, где структура похожа на структуру Си, пусть и в парадигме обобщённого программирования C++, а класс это тот самый новый ООП подход при переходе от Си к C++.
V>
Инкапсуляция и свойства
V>Ошибки произошли потому, что я неявно использовал часть инкапсуляции, то есть механизм сокрытия данных.
Что интересно, в русской вики просят не путать инкапсуляцию с сокрытием (в заголовке), но все же употребляют термин "сокрытие" в определении.
V> Сам термин инкапсуляция используется несколько шире, чем только лишь в ООП. И даже в ООП он не ограничивается размещением данных и методов в одном компоненте. Иногда, ровно наоборот.
Инкапсуляция в широком (более широком, чем модификатор доступа) понимании является дуализмом к абстракции. Т.е. там, где рождается абстракция, одна часть кода абстрагируется от каких-то вещей, а другая — инкапсулирует их. И эти вещи — не только лишь поля и методы, но и подходы, алгоритмы, способы. Абстракция здесь тоже более широкая, чем в ООП. Т.е. это не абстрактный класс, не только лишь он. Например, мне нужно в клиентском коде отсортировать строки. Я использую абстракцию sort, передаю ей контейнер, с которым она (абстракция) умеет работать. Вот, пожалуйста, у меня есть абстракция sort, которая с моей стороны выглядит как вызов метода, а с другой стороны этой абстракции инкапсулирован конкретный алгоритм сортировки. Пока никаких модификаторов видимости мы не встретили.
Идем дальше. Сортировать строки нужно каким-то странным способом. Для этого есть решение. Абстракция sort может быть в свою очередь абстрагирована от способа сравнения строк (да и вообще элементов). Значит ли это, что все известные и неизвестные способы сравнения строк должны быть размещены в классе строки? Уверен, что нет. Т.е. ничего нам не мешает скрыть способ сравнения элементов от алгоритма сортировки, не размещая этот способ внутри класса сортируемого элемента. Итак, сокрытие есть, но сокрытия в смысле модификаторов видимости и размещения кода в том же компоненте — нет.
Не топлю за ООП, лишь показываю, что выбран странный способ демонстрировать катастрофу ООП на примере сравнения количества кода RECT/CRectangle после применения инкапсуляции.
Инкапсуляция — это когда я подхожу к умывальнику и поворачиваю кран, то способ сдерживания напора воды в трубе — он, оказывается, инкапсулирован. Или когда сажусь в автомобиль и поворачиваю ключ зажигания — то хрен его знает, что там происходит... В теории я знаю, но особенности реализации скрыты за простой абстракцией (ключ зажигания). Термин инкапсуляция — он об этом. ООП виновато лишь в том, что прибило термин к модификаторам доступа полей и методов.
V>Но что если мне нужен доступ к закрытым полям данных. На помощь приходит шаблон проектирование "Свойство". Одни и те же шаблоны проектирования можно реализовывать по разному. Воспользуюсь самым примитивным известным мне способом.
Поля все же скрывают не от прихоти. struct Rect все же далеко не самый удачный пример для сокрытия полей и реализации свойств. У класса нет поведения (кроме тривиального), нет никаких абстракций, его сложно сломать. Рассмотрим не Rect, а какой-нибудь словарь на базе хэштаблицы или rb-дерева... Нужен ли нам доступ к закрытым полям данных такого класса?
Да, полагаю, что острая необходимость может возникнуть, но мы при этом фактически разрушаем абстракцию. Т.е. мы до тонкости должны представлять реализацию, должны быть привязаны к конкретным реализациям, которые не сильно отличаются от нашего представления об их устройстве. В случае контейнера сокрытие полей данных — уже не прихоть, а некий способ затруднить работу с компонентом за рамками предлагаемой абстракции, призванной уберегать пользователя от сложности реализации.
V>Пример стал чуть ближе к классическому классу, можно было бы даже заменить print_crectangle на CRectangle.print(). Тем не менее разница в количестве кода по сравнению со структурой на лицо, а ведь здесь ещё нет ни конструктора с деструктором, ни много чего ещё.
пихать print внутрь CRectangle — сомнительная затея, до тех пор, пока нет как минимум одного канонического способа его напечатать, включая устройство вывода (qDebug). Всегда может кому-то потребоваться свой способ и устройство. А все способы не засунуть в CRectangle. Так же, как и все способы сравнения строк не впихнуть в строку.
V>
Многомерные модели данных
Причем тут вообще это? Зачем вообще противопоставлять ООП, модели данных и способы их хранения и обработки?Абстракции и машинные коды
Здравствуйте, samius, Вы писали:
S>Причем тут вообще это? Зачем вообще противопоставлять ООП, модели данных и способы их хранения и обработки?
А это как раз самое главное, а вовсе не катастрофа ООП за которую многие зацепились. С точки зрения абстракций, данные и операции над ними везде одинаковые, просто в одном случае их обработкой занимается язык C++ (массивы и классы), в другом Lua (таблицы вложенные друг в друга), в третьем Sql (связанные таблицы).
В конечном итоге данные обрабатываются с помощью машинных команд наиболее близко представимых в виде команд ассемблера. Вряд ли кто-то будет на основе имеющихся команд создавать и использовать в продакшене нестандартные типы, вроде арифметических большей точности или хранящих биты иначе, чем заложено в архитектуре процессора, так как это замедлит работу программы.
Ассемблер. Арифметические инструкции
В остальном всё тоже самое.
Ассемблер. Логические инструкции
Инструкции перехода, возврата из функции и так далее и тому подобное. К тому же операции выполняются в регистрах, а процессор имеет несколько уровней кэша.
С самого начала программисты пользуются языками высокого уровня абстракции, но даже на языке низкого уровня абстракции не обходится без абстракций.
Реляционные базы данных и объектно-ориентированное программирование
Возьмём для примера таблицу из базы данных, в ней как правило есть данные и первичный ключ, хотя первичного ключа может и не быть. В дополнение ещё можно добавить индексы, опять же именно в дополнение. Реализовать такое в C++ можно с помощью ассоциативного массива парами ключ-значение, а связывание и вовсе указателями, то есть обойтись даже без ключа. И обратное тоже верно, классы и объекты данных не сложно поместить в таблицы и вести обработку данных.
Только вот в базах данных:
1) Сокрытие данных: Столбцы данных не скрываются модификаторами доступа (public, protected, private).
2) Объединение данных и функций: Функции могут работать сразу со всеми данными базы (они не функции-члены или методы таблицы).
3) Наследование: Можно обходиться без наследования и всё работает.
Для своей универсальной модели данных Qt выбрал двухмерную модель, что является частным случаем многомерной модели, с вложениями самой себя в ячейки (QModelIndex, QAbstractItemModel).
C++ имеет модификаторы доступа для сокрытия данных, но никто не заставляет ими пользоваться, скорее ими пользуются потому, что они есть. Правда в книгах часто пишут, что вы получите повышенную безопасность, и даже не вы лично, а те кто будет пользоваться вашими решениями. А как пользователь вы типа не сломаете концепцию которую вложили программисты, так как у вас будет безопасный открытый интерфейс для управления данными.
Однако, когда дело доходит до баз данных, оказывается что всё это не важно. Нет таких возможностей, да и фиг с ними. И даже если кто-то где-то пытался реализовать, то не факт, что это будут использовать. Да и в Си плевали на ООП с высокой колокольни, по сути хватило бы обобщённого программирования для прокачки этого языка, был бы Си+ или Си с шаблонами, а не Си++.
Вопрос в том, получаем ли мы фейл уже на этапе связывания данных и функций (инкапсуляция) или нет.
+) Плюс в том, что нет необходимости явного указания аргументов при вызове функций.
-) Минус в том, что функцию нельзя использовать повторно как раз из-за невозможности изменить аргументы.
Изменение языков программирования и архитектура программ
Так же хотел бы отметить, что это тема не про изменения языков программирования, так как те не препятствуют созданию не общераспространённых архитектур программ, или архитектур, которые построены не на классическом принципе ООП.
V>
Абстракции и машинные коды
V>Здравствуйте, samius, Вы писали:
S>>Причем тут вообще это? Зачем вообще противопоставлять ООП, модели данных и способы их хранения и обработки?
V>А это как раз самое главное, а вовсе не катастрофа ООП за которую многие зацепились. С точки зрения абстракций, данные и операции над ними везде одинаковые, просто в одном случае их обработкой занимается язык C++ (массивы и классы), в другом Lua (таблицы вложенные друг в друга), в третьем Sql (связанные таблицы).
Хоть, C++ считается и ООП языком, точнее, поддерживающим ООП, из этого вовсе не следует, что модель данных ООП программы должна быть организована в лучших канонах ООП. ООП программа вполне может работать с потоком байт, не делая вид что работает с коллекцией объектов, каждый из которых моделирует "поведение байта" и наследуется от CObject.
Еще раз, ООП программа — это программа, написанная с ипользованием ООП практик. Это не есть тождественное равенство ООП модели данных.
V>В конечном итоге данные обрабатываются с помощью машинных команд наиболее близко представимых в виде команд ассемблера. Вряд ли кто-то будет на основе имеющихся команд создавать и использовать в продакшене нестандартные типы, вроде арифметических большей точности или хранящих биты иначе, чем заложено в архитектуре процессора, так как это замедлит работу программы.
А разве DECIMAL и NUMERIC уже поддерживаются ахитектурой процессора?
V>Возьмём для примера таблицу из базы данных, в ней как правило есть данные и первичный ключ, хотя первичного ключа может и не быть. В дополнение ещё можно добавить индексы, опять же именно в дополнение. Реализовать такое в C++ можно с помощью ассоциативного массива парами ключ-значение, а связывание и вовсе указателями, то есть обойтись даже без ключа. И обратное тоже верно, классы и объекты данных не сложно поместить в таблицы и вести обработку данных.
V>Только вот в базах данных:
V>1) Сокрытие данных: Столбцы данных не скрываются модификаторами доступа (public, protected, private).
V>2) Объединение данных и функций: Функции могут работать сразу со всеми данными базы (они не функции-члены или методы таблицы).
V>3) Наследование: Можно обходиться без наследования и всё работает.
Да кто же вас заставляет наследовать int от byte-а при работе с потоками данных или с записями таблиц? Если не нужна объектная модель данных, то и не надо ее вкорячивать.
ООП программа != ООП модель данных
V>Для своей универсальной модели данных Qt выбрал двухмерную модель, что является частным случаем многомерной модели, с вложениями самой себя в ячейки (QModelIndex, QAbstractItemModel).
V>C++ имеет модификаторы доступа для сокрытия данных, но никто не заставляет ими пользоваться, скорее ими пользуются потому, что они есть. Правда в книгах часто пишут, что вы получите повышенную безопасность, и даже не вы лично, а те кто будет пользоваться вашими решениями. А как пользователь вы типа не сломаете концепцию которую вложили программисты, так как у вас будет безопасный открытый интерфейс для управления данными.
Вот это не годится, пользоваться потому, что они есть. Любой инструмент нужно использовать не потому, что он есть, а потому, что он позволяет решить конкретную проблему. Инкапсуляция в типе RECT не решает ничего, т.к. этот тип не обладает поведением, отличным от тривиальной структуры.
V>Однако, когда дело доходит до баз данных, оказывается что всё это не важно. Нет таких возможностей, да и фиг с ними. И даже если кто-то где-то пытался реализовать, то не факт, что это будут использовать. Да и в Си плевали на ООП с высокой колокольни, по сути хватило бы обобщённого программирования для прокачки этого языка, был бы Си+ или Си с шаблонами, а не Си++.
И еще раз, ООП программа != ООП модель данных. DTO, Anemic Domain Model — все это обычные практики.
V>Вопрос в том, получаем ли мы фейл уже на этапе связывания данных и функций (инкапсуляция) или нет.
V>+) Плюс в том, что нет необходимости явного указания аргументов при вызове функций.
V>-) Минус в том, что функцию нельзя использовать повторно как раз из-за невозможности изменить аргументы.
Если наследовать ужа от носорога, потому что так написано в книжке, фейл гарантирован. Смотря, конечно, что является критерием выполненной работы. Если вам нужно выполнить запрос к таблице и показать резульат, то занятие построением богатой бизнес модели в каноническом ООП с наследованием Student от Person-а и отображение данных из таблицы в модель — оно очень увлекательно и познавательно. Но не приближает к выполнению задачи.
Еще раз немного с другого боку: ООП — это способ организации кода, стиль программирования, в котором объекты обмениваются сообщениями. При этом модель данных вовсе не обязана быть объектом, модель данных может быть вполне себе сообщением между ООП компонентами программы. Сообщения в ООП программе — это нечто тривиальное, что вообще говоря, не должно обладать собственным поведением. Т.е. это идентификаторы, параметры методов, строки таблицы данных, struct RECT-ы, результаты запросов в бд, или даже команды. Команды, конечно, можно организовать в иерархию. Но объектизация команды — это ближе к решению, чем к модели данных.
Таким образом, мы получаем ответ на вопрос, может ли в ООП программе использоваться неинкапсулированный и неотнаследованный ни от чего struct RECT? Мой ответ — да, безусловно. Хотя, у многих (или даже у большинства) апологетов ООП (к которым я себя не причисляю) от такого ответа пригорит.
V>Катастрофа ООП
Эту статью уже обсуждали.
Вообще, почитай ответы Sinclair насчёт ООП, много полезного узнаешь. Для понимания с этого можно начать.
На мой взгляд, мы видим все эти проблемы из-за неумения программиста переходить от модели предметной области после её анализа к конкретной модели в виде классов с нашими шаблонами, т.е. конкретного дизайна программы с обсёрверами, локаторами, mvc, стейтом, прототипом или просто набором классов каким-то образом связанных. Отсюда и нытьё, что ООП всё, а на самом деле всё только с ними самими, любителями учится по статьям, ютубу и конференциям.
V>>Катастрофа ООП
K>Эту статью уже обсуждали.
1) Я знаю, и там, кстати, ничего полезного не было даже про ООП, было только "нытьё" про то что вы не умеете его готовить.
2) Ещё раз повторяю, это тема про многомерные модели данных, которые так или иначе очень много где используются, хотя полностью игнорируют принципы ООП.
Пока скажем так, беседа не пошла, но мысль я записал, так что всё нормально. Может в будущем будут интересные ответы или я сделаю ещё какие-либо выводы на основе имеющихся.
V>[q]
V>C++ — ужасный объектно-ориентированный язык. Ограничение вашего проекта до C означает, что люди не напортачат ни с какой идиотской «объектной моделью».
V>Линус Торвальдс, создатель Linux
после 10 раз прочтения понял, что Торвальдс не простой маразматик, а в его словах есть здравое зерно. Если язык позволяет писать плохо, значит плохой язык (другой вопрос, что в качестве идеала он приводит C).
Часто на проектах сталкиваюсь с излишним усложнением. Вместо того чтобы написать простой класс Field пишут для него интерфейс IField и от него уже наследуются. Когда ты пишешь на Java, это напрягает не сильно — указатели везде и ты на этом фоне выглядишь неплохо. Но в С++, когда ты видишь shared_ptr, ты понимаешь, что где-то вызвали new и это дорого. Причем дорого неоправданно. Этого легко можно избежать. Просто не надо делать на каждый класс свой интерфейс. В данном случае наследование вводит излишнюю сложность, просаживает производительность и не даёт ничего взамен. Но ты пришёл на проект слишком поздно. "Отцы-основатели" уже напилили интерфейсы на всё и вся и перелопатить кучу legacy уже нет возможности. После этого остаётся только садиться и писать подобные статьи, чтобы твой следующий legacy возможно не был настолько ужасным.
Само разграничение на struct и class очень хорошо описали в Core quidelines. Если у вас поля стуктуры инвариантны, надо писать struct. Иначе — class. То есть не надо писать class CRect. Это дейстительно глупо. Что и показала статья. Но возьмём другой пример из стандарта: std::optional. Он поддерживает доступ одновременно и к булевому флажку означающему отсутствие, и к значению, которое может отсутствовать. Вот тут имеется конкретное нарушение инкапсуляции. В коде !opt ? opt.value() : 0 не каждый при беглом просмотре обнаружит ошибку. Тут бы стоило запретить доступ к этим полям (в пример можно поставить тот же std::option из Rust). Казалось бы Rust к ООП имеет весьма далёкое отношение. Но вот такие вот дела... Инкапсуляция в нём представлена лучше.
Ну и относительно ООП как парадигмы. Может действительно ООП плохая парадигма, потому что она позволяет писать плохо? С другой стороны альтеративы не видно. Можно сказать, что функциональный подход. Но он то тоже не идеален. Тот же пример сортировки. Запрет на изменяемость просто убъёт всю производительность. Вроде вам запретили писать плохой код, но не разрешили же писать и хороший.
SP>Ну и относительно ООП как парадигмы. Может действительно ООП плохая парадигма, потому что она позволяет писать плохо? С другой стороны альтеративы не видно. Можно сказать, что функциональный подход. Но он то тоже не идеален. Тот же пример сортировки. Запрет на изменяемость просто убъёт всю производительность. Вроде вам запретили писать плохой код, но не разрешили же писать и хороший.
https://guide.elm-lang.org/
В разделе приложения понравилось описание того что есть тип. ООП по мне это больше к архитектуре(кости). ФП это кровь и плоть.
SP>Здравствуйте, velkin, Вы писали:
V>>[q]
V>>C++ — ужасный объектно-ориентированный язык. Ограничение вашего проекта до C означает, что люди не напортачат ни с какой идиотской «объектной моделью».
V>>Линус Торвальдс, создатель Linux
SP>после 10 раз прочтения понял, что Торвальдс не простой маразматик, а в его словах есть здравое зерно. Если язык позволяет писать плохо, значит плохой язык (другой вопрос, что в качестве идеала он приводит C).
Всякий кулик свое болото хвалит. Для разработки ядра ОС C++ создал бы больше проблем чем решил. Здесь Торвальдс прав.
Но Торвальдс отнюдь не специалист по куче других областей разработки где ООП и C++ в частности (а также куча других языков) подходят гораздо лучше чем C.
Так что он не простой маразматик, но все же человек с ограниченными взглядами который плевать хотел на мнение других людей (которые в других областях понимают лучше него).
Люблю такие статьи: автор берёт максимально притянутый за уши пример, и на нём показывает почему всё плохо. Видимо на чём-то более реалистичном недостатки начинают выглядеть неубедительно.
V>А по хорошему я не должен дописывать ничего подобного, чтобы разграничить подходы, где структура похожа на структуру Си, пусть и в парадигме обобщённого программирования C++, а класс это тот самый новый ООП подход при переходе от Си к C++.
То есть с вашей точки зрения свойства добавляются исключительно чтобы "разграничить подходы"? Окай.
V>Но сделав функцию методом, а потом и прибив её к внутреннему состоянию класса мы сделали алгоритм не повторно используемым.
Оооо... А как вы собрались "повторно использовать" функцию вычисления площади прямоугольника в рамках одной программы?
V>Конечно, можно извратиться
Можно, ведь для этого и написана эта статья.
V>Хотя разумно было бы разделить поля прямоугольника на:
V>1) Двухмерная координата (она же точка).
V>2) Двухмерный размер.
Почему?
V>В классе появилось лишнее делегирование, хотя это позволяет мне не менят код вывода значений. И хотя мои примеры чисто условны, тоже самое будет к примеру в такой библиотеке как Qt. Там тоже любят подобное сквозное делегирование всего и вся.
И насколько я знаю там для этого куда более веские основания, а не "шоб було".
V>Но проблема не просто в том, что код дублируется многократно. Казалось бы не дублируй и всё. Но кто в наше время пишет свои велосипеды, разве что для обучения. А по факту имеем фрейморки, и классы прямоугольников от разных поставщиков:
И со структурами будет то же самое.
V>Всё это были просто размышлизмы с простейшими примерами. На основе этого рано делать какие-либо выводы. Но можно обсудить кто что думает.
Думаю что неплохо было бы, если бы автор продемонстрировал полиморфизм на основе структур.
V>Или взять Lua, там нет классов и прочего, а есть таблицы.
Чего прочего, кроме классов там нет?
В Visual Basic (до перехода на VB.NET) тоже не было классов.
Таблицы в Lua это самые обычные объекты, ничем совершенно не отличающиеся от объектов JavaScript.
V>Для начала создам структуру и класс на языке C++ в обобщённой парадигме программирования.
Не существует никакой "парадигмы обобщённого программирования" популярной среди пользователей STL. На С++ можно писать:
— как на С или на Паскале с помощью модулей (через класс-одиночку со спец ограничениями), функций и "структурно/функциональной парадигмы";
— или пользоваться абстракцией данных (АТД — абстрактные типы данных) используя классы и "объектную парадигму".
Изначальный C++ ограничен:
— семантикой копирования (менее эффективный код);
— "шаблоны времени компиляции" (template<>) не имеют интерфейсов (переносят ошибки статического связывания в template<> от времени объявления на время инстанцирования, т.е. от программиста разработчика к программисту пользователю);
— "шаблоны времени компиляции" (template<>) в реальных компиляторах не имеют нормальных средств отладки (например не инстанцируются во временный файл исходника с текстом подставленных имен).
без интерфейсов нельзя написать так "interface Iworld {list_of_names}; template<Iworld world, Ilight light, int world_num>..."
Уже только "семантика копирования, виртуальные функции и АТД" дают большие преимущества для улучшения структуры кода и данных программы, даже если писать модули структурными концепциями. Применение "шаблонов проектирования" это любопытная тема, т.к. позволяет реализовать уникальные классы предметной области через хорошо известные стандартные способы организации кода и данных и универсальные элементарные классы.
===
в двух словах — "это всё слишком сложно!!!"
Ну, чего-то подобного я ожидал после того, как лет пять назад на собеседовании на вопрос про деревья в БД начал рассказывать про вложенные множества и транзакционное замыкание. Я увидел широкие глаза интервьюера и робко предложил хранить родителя или родителей в строке. Вот после этого ответа он расцвел просто.
Привыкайте, старики. Ваш код и ваши знания нахрен никому в современном мире не нужны. Нафигачим микросервисов и будем радоваться простоте! Что самое обидное — это правильный подход. Иначе ваш код никто не сможет поддерживать, для современных программистов это слишком сложно. Так что я двумя лапками за микросервисы!!! Да и мороки меньше. Пусть у манагера голова болит что со всей этой лапшой делать, слава богу разгребать не заставляют, как раньше. Теперь лапша — это стандарт!
V>Всё это были просто размышлизмы с простейшими примерами. На основе этого рано делать какие-либо выводы. Но можно обсудить кто что думает.
Статья банальный кликбейт.
ООП отлично ложится в UI и более того была куча реализацией более успешных и менее успешных.
Куча примеров в базовых либах для java, C# и т.д.
Когда в ООП начинают приводить пример и считать площажь прямо внутри, то это не инструмент плохой, а кривая модель!
В общем случае можно вполне обойтись без ООП и писать в процедурно-функциональном стиле, но бывают модели, где без ООП будет сложно.
При этом некорректное и неуместное использование инструмента сводят к плохому инструменту.