select 'Hello, World!'
The single biggest challenge to learning SQL programming is unlearning procedural programming (Joe Celko)
STRING_SPLIT - новая встроенная функция в MS SQL Server 2016
11.03.2016
|
Olaf
 |
Привет, Всем!
На днях вышел в свет SQL Server 2016 Release Candidate (RC0). В качестве заявленных дополнений фигурирует встроенная функция STRING_SPLIT для деления строки на части с возможностью указать разделитель.
Казалось бы, в наши дни такой функциональностью уже никого не удивишь, т.к. существует около десятка способов реализовать аналог самостоятельно, причем один из вариантов появился совсем недавно в версии 2016 с функцией openjson. Тем не менее, хотелось бы посмотреть на реализацию из «коробки» и сравнить с производительностью существующих решений.
Мой тест будет основываться на постах из обсуждения split(somestring,',') в T-SQL, которое здесь недавно проходило, с учетом ошибки, которую я допустил для варианта №4 на большом количестве элементов. Кроме того, все пользовательские функции я снабдил дополнительным параметром – много символьный разделитель (!)
Рассматривается 8 способов поделить строку на части через разделитель:
1. Цикл
2. CTE
3. XML
4. Таблица
5. CLR
6. OPENJSON
7. LIKE, PATHINDEX, CHARINDEX
8. STRING_SPLIT
Для сравнения производительности используется вспомогательная таблица dbo.table2, которая содержит массив элементов фиксированной длины. В качестве ключа id выступает идентификатор, совпадающий с количеством элементов в массиве. Разделителем элементов является запятая ',' Тест выполняется с помощью утилиты SQLQueryStress через запуск решения 10 раз, на основании полученных данных вычисляется среднее время выполнения.
Тестовые данные
Для подготовки данных использовал...
Решение
Реализовано в запросах...
Результат
Для наглядности результаты сравнения производительности представлены в виде графика. Ось Y — логарифмическая.
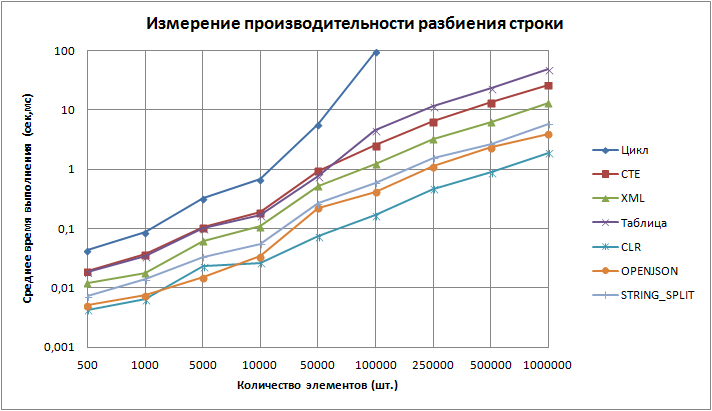
Исходные данные содержатся в таблице.
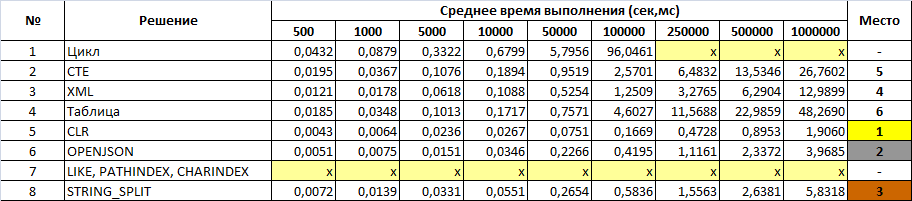
Вывод
Испытание полностью выдержали только 6-ть решений из 8-и, т.е. решения у которых среднее время выполнения запроса меньше 10 минут, результат преобразования правильный и не возникло исключительных ситуаций в ходе выполнения. Первое место по-прежнему удерживает вариант номер 5 с CLR реализацией. Причем исходя из данных представленных в таблице видно, что время выполнения увеличивается пропорционально количеству данных. Второе место уверенно сохраняет OPENJSON решение. Стоит отметить, что начиная со значения в 50 000 элементов наблюдается расхождение в два раза по сравнению с CLR функцией, в то время как предыдущие результаты отличались в третьем знаке после запятой. Новая встроенная функция STRING_SPLIT незначительно отстает от варианта с OPENJSON и занимает 3-е место. XML подход показал стабильное время на всех участках эксперимента и переходит на 4-е место. 5-я строчка рейтинга достается решению с использованием CTE, причем до отметки в 100 000 элементов, данный подход отставал в третьем знаке после запятой от реализации с использованием справочной таблицы с числами. В итоге замыкает шестерку решение под номером 4, показатели которого стали ухудшаться с отметки в 100 000 элементов.
Еще пара слов о решениях, которые выбыли из конкурса.
Вариант номер 7 (LIKE, PATINDEX,CHARINDEX) — длительное время выполнения даже на маленьких объемах данных заставило исключить его. Для решения номер 1 с циклом начиная с 250 000 элементов увеличилось время выполнения и перевалило за 10 минут, поэтому было принято решение исключить и этот вариант.
P.S. Новая встроенная функция STRING_SPLIT обладающая всеми преимуществами варианта из "коробки" показала неплохую производительность. Пожалуй единственный недостаток заключается в сепараторе, который может быть не больше одного символа. Возможно при условии, что вы хорошо знаете свои данные этот недочет можно обойти.
На днях вышел в свет SQL Server 2016 Release Candidate (RC0). В качестве заявленных дополнений фигурирует встроенная функция STRING_SPLIT для деления строки на части с возможностью указать разделитель.
Syntax
STRING_SPLIT ( string , separator )
Arguments
string — Is an expression of any character type (i.e. nvarchar, varchar, nchar or char).
separator — Is a single character expression of any character type (e.g. nvarchar(1), varchar(1), nchar(1) or char(1)) that is used as separator for concatenated strings.
Return Types
Returns a single-column table with fragments. The name of the column is value. Returns nvarchar if any of the input arguments are either nvarchar or nchar. Otherwise returns varchar. The length of the return type is the same as the length of the string argument.
Казалось бы, в наши дни такой функциональностью уже никого не удивишь, т.к. существует около десятка способов реализовать аналог самостоятельно, причем один из вариантов появился совсем недавно в версии 2016 с функцией openjson. Тем не менее, хотелось бы посмотреть на реализацию из «коробки» и сравнить с производительностью существующих решений.
Мой тест будет основываться на постах из обсуждения split(somestring,',') в T-SQL, которое здесь недавно проходило, с учетом ошибки, которую я допустил для варианта №4 на большом количестве элементов. Кроме того, все пользовательские функции я снабдил дополнительным параметром – много символьный разделитель (!)
Рассматривается 8 способов поделить строку на части через разделитель:
1. Цикл
| Код функции | |
| |
2. CTE
| Код функции | |
| |
3. XML
| Код функции | |
| |
4. Таблица
| Код функции | |
| |
5. CLR
| Код функции | |
| |
6. OPENJSON
7. LIKE, PATHINDEX, CHARINDEX
8. STRING_SPLIT
Для сравнения производительности используется вспомогательная таблица dbo.table2, которая содержит массив элементов фиксированной длины. В качестве ключа id выступает идентификатор, совпадающий с количеством элементов в массиве. Разделителем элементов является запятая ',' Тест выполняется с помощью утилиты SQLQueryStress через запуск решения 10 раз, на основании полученных данных вычисляется среднее время выполнения.
Тестовые данные
Для подготовки данных использовал...
| Сценарий | |
| |
Решение
Реализовано в запросах...
| Сценарий | |
| |
Результат
Для наглядности результаты сравнения производительности представлены в виде графика. Ось Y — логарифмическая.
Исходные данные содержатся в таблице.
Вывод
Испытание полностью выдержали только 6-ть решений из 8-и, т.е. решения у которых среднее время выполнения запроса меньше 10 минут, результат преобразования правильный и не возникло исключительных ситуаций в ходе выполнения. Первое место по-прежнему удерживает вариант номер 5 с CLR реализацией. Причем исходя из данных представленных в таблице видно, что время выполнения увеличивается пропорционально количеству данных. Второе место уверенно сохраняет OPENJSON решение. Стоит отметить, что начиная со значения в 50 000 элементов наблюдается расхождение в два раза по сравнению с CLR функцией, в то время как предыдущие результаты отличались в третьем знаке после запятой. Новая встроенная функция STRING_SPLIT незначительно отстает от варианта с OPENJSON и занимает 3-е место. XML подход показал стабильное время на всех участках эксперимента и переходит на 4-е место. 5-я строчка рейтинга достается решению с использованием CTE, причем до отметки в 100 000 элементов, данный подход отставал в третьем знаке после запятой от реализации с использованием справочной таблицы с числами. В итоге замыкает шестерку решение под номером 4, показатели которого стали ухудшаться с отметки в 100 000 элементов.
Еще пара слов о решениях, которые выбыли из конкурса.
Вариант номер 7 (LIKE, PATINDEX,CHARINDEX) — длительное время выполнения даже на маленьких объемах данных заставило исключить его. Для решения номер 1 с циклом начиная с 250 000 элементов увеличилось время выполнения и перевалило за 10 минут, поэтому было принято решение исключить и этот вариант.
P.S. Новая встроенная функция STRING_SPLIT обладающая всеми преимуществами варианта из "коробки" показала неплохую производительность. Пожалуй единственный недостаток заключается в сепараторе, который может быть не больше одного символа. Возможно при условии, что вы хорошо знаете свои данные этот недочет можно обойти.
| 11.03.2016 11 комментариев |
O>Рассматривается 8 способов поделить строку на части через разделитель:
O>5. CLR
Спасибо, а кодом самой функции не поделитесь?
Теперь вот только агрегата для строк, аналога String.Join из .NET, не хватает.
O>>Рассматривается 8 способов поделить строку на части через разделитель:
O>>5. CLR
X>Спасибо, а кодом самой функции не поделитесь?
Я использовал вариант от Adam Machanic из статьи SQLCLR String Splitting Part 2: Even Faster, Even More Scalable
O>Я использовал вариант от Adam Machanic из статьи SQLCLR String Splitting Part 2: Even Faster, Even More Scalable
Красивый код. Обычно в примерах постят что-то уровня "допилить напильником", тут прямо приятное исключение
O>Здравствуйте, xy012111, Вы писали:
O>>>Рассматривается 8 способов поделить строку на части через разделитель:
O>>>5. CLR
X>>Спасибо, а кодом самой функции не поделитесь?
O>Я использовал вариант от Adam Machanic из статьи SQLCLR String Splitting Part 2: Even Faster, Even More Scalable
но он не CSV
http://rsdn.org/forum/dotnet/3303143.1
O>>Я использовал вариант от Adam Machanic из статьи SQLCLR String Splitting Part 2: Even Faster, Even More Scalable
S> но он не CSV
S>http://rsdn.org/forum/dotnet/3303143.1
Не понял вас, что означает — он не CSV? Разбирается строка любой длины, содержащая элементы с произвольным разделителем.
O>Здравствуйте, Serginio1, Вы писали:
O>>>Я использовал вариант от Adam Machanic из статьи SQLCLR String Splitting Part 2: Even Faster, Even More Scalable
S>> но он не CSV
S>>http://rsdn.org/forum/dotnet/3303143.1
O>Не понял вас, что означает — он не CSV? Разбирается строка любой длины, содержащая элементы с произвольным разделителем.
CSV это не только разделитель строк
Но и QuoteChar
https://ru.wikipedia.org/wiki/CSV
X>Теперь вот только агрегата для строк, аналога String.Join из .NET, не хватает.
В новой версии SQL Server vNext CTP 1.0 появилась функция STRING_AGG, которая конкатенирует строки (значения) через разделитель.
Неплохо бы еще сравнить потребление памяти. Это тоже важно при выборе решения в конкретной ситуации.
При замене этого
на
план строится исходя из средне-сатистических ожиданий о работе mySplitterFunc, и вот тут начинается интересное
у clr — estimated number of rows — 1000
у string_split рекордно низкие 50 (!)
у всех остальных в пределах 100
от аргументов оценки, естественно, никак не зависят
поэтому более менее нормально на больших списках работает только clr версия
и то ее нужно править, каждый раз задавая N
R>Для реальных задач (split(somestring,',') в T-SQL) как правило нужна работа запросов типа
R>
R>При замене этого
R>на
R>
R>план строится исходя из средне-сатистических ожиданий о работе mySplitterFunc, и вот тут начинается интересное
R>у clr — estimated number of rows — 1000
R>у string_split рекордно низкие 50 (!)
R>у всех остальных в пределах 100
R>от аргументов оценки, естественно, никак не зависят
Безусловно это так, но часть пользовательских функций может быть переведена в inline table valued функции и тогда появится другой план и совсем другая оценка. А вы можете сказать, как поменяется план запроса и его производительность, если бы оптимизатор повысил точность оценки количества данных возвращаемых функцией (CLR, UDF,встроенная) с 50 до 1000 в примере запроса, который вы привели? Т.е. насколько велико влияние оценки предполагаемого количества записей, которые вернет функция на производительность в этом простом запросе?
R>поэтому более менее нормально на больших списках работает только clr версия
R>и то ее нужно править, каждый раз задавая N
R>
Хотелось бы понять на каком объеме данных и по каким критериям вы проверяли производительность.
Да, CLR впереди всех, но встроенные функции от Microsoft (string_split, openjson) не сильно отстают от лидера. Кроме того, если возвращаться к реальным задачам, озвученным из другого топика, то у автора списки хранятся как записи в другой таблице, причем возможно произвольной длины, поэтому там предполагается решение вида, где top N не сработает.
И вот что интересно, а вы пробовали задавать top N, где N > больше 1000 и на какой версии? Потому что, до 1000 оптимизатор справляется с оценкой предполагаемого количества возвращаемых записей, а вот для всех случаев свыше 1000 ставит estimated number of rows = 1000 в независимости от значения N.
Т.е. насколько велико влияние оценки предполагаемого количества записей, которые вернет функция на производительность в этом простом запросе?
Чтобы долго не разводить, я приведу один очень-очень тупой пример. Временная таблица на 100к значений и выборки по ней с фильтром на 2 колонки.
Предлагаю повторить и убедиться.
dbo.SplitInts — это наш внутренний clr-splitter уже сразу на инты. принципиально вряд ли чем-то отличается от любого другого.
O>И вот что интересно, а вы пробовали задавать top N, где N > больше 1000 и на какой версии? Потому что, до 1000 оптимизатор справляется с оценкой предполагаемого количества возвращаемых записей, а вот для всех случаев свыше 1000 ставит estimated number of rows = 1000 в независимости от значения N.
Да, есть методики обмана через cross apply. Где-то до 50-100к работают.